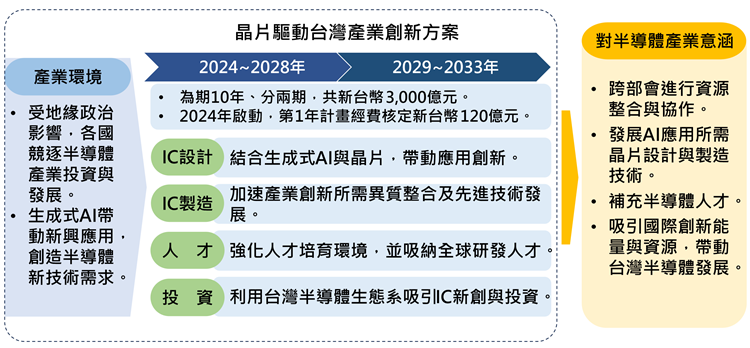
DIGITIMES Research觀察,邊緣端AI晶片市場競爭激烈,晶片特性相較於雲端應用為高運算效率、低延遲、運算力小、低功耗。隨著邊緣運算市場需求明確,各晶片業者持續開發提升邊緣運算力的技術,如指標業者NVIDIA與英特爾(Intel)利用降低數據精度運算與發展融合層數推論引擎,以滿足邊緣AI對快速、精準預測推論能力的需求。
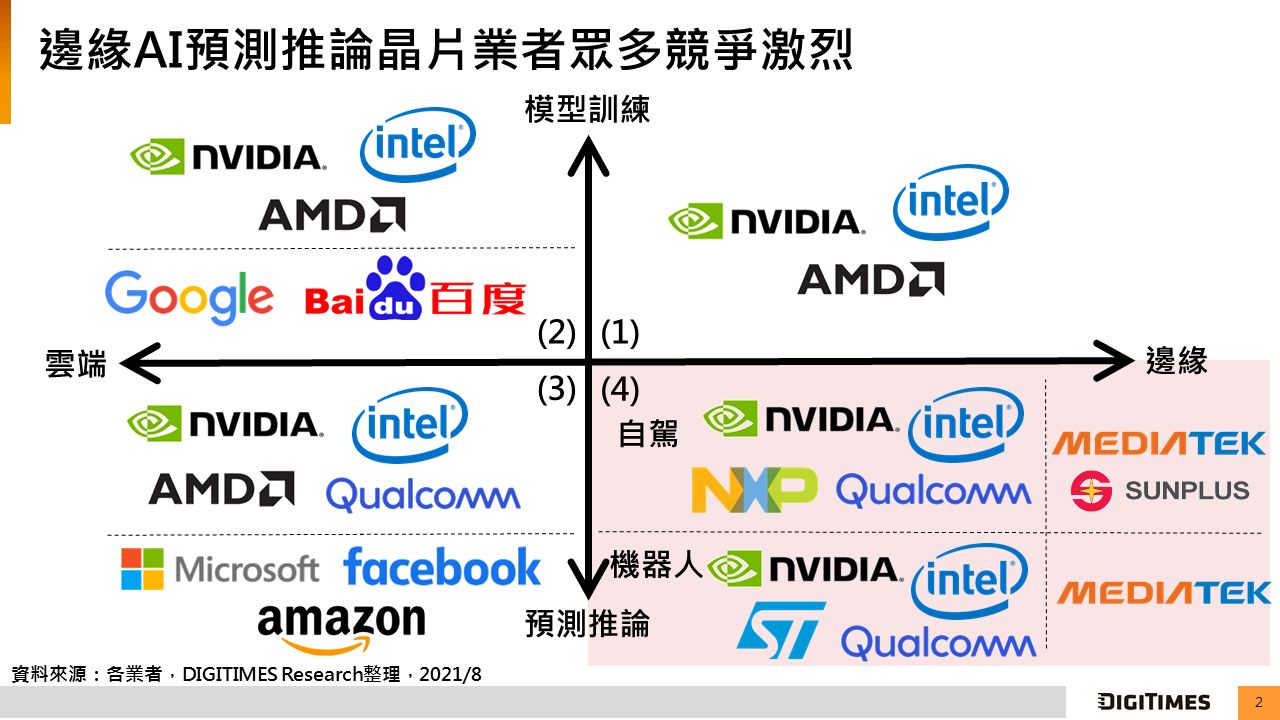
人工智慧晶片可依運作位置(雲端或邊緣)與功能(模型訓練或預測推論)區分,目前發展邊緣推論類別的晶片業者數量最多,競爭激烈,國外代表業者包含NVIDIA、英特爾、高通(Qualcomm)、恩智浦(NXP),國內以聯發科、凌陽科技為代表。
邊緣AI預測推論模型為深度學習框架模型建構與數據訓練後壓縮而成,在GitHub平台,以由Google專業團隊維護支持的TensorFlow框架活躍度最高,特色為功能強、支援多數常見語言,涵蓋從雲端到終端所有平台,成為許多開發者使用的框架首選,但仍存在系統設計複雜、原始碼新舊版本無法通用、框架運作速度慢的缺點。
NVIDIA與英特爾為達成邊緣推論引擎AI運算速度提升,發展將浮點運算精度由FP32轉換為INT8的低精度數值方式運算,且不失準確度,其中,NVIDIA提出垂直與水平層間與張量融合的技術,以減少演算層數,如NVIDIA於7月中發布的TensorRT 8最佳化Transformer模型BERT-Large,部署在V100 GPU上運行,只需1.2毫秒即推論完成;英特爾也提出合併無中介碼程序技術。
至於所支援的邊緣端硬體部分,以英特爾推論引擎可選擇的晶片類型較多樣化,包含CPU、CPU內含顯示晶片、VPU、FPGA,而NVIDIA現階段僅有GPU可選擇。