評估申請
登入
科技網
未來車供應鏈
蘋果供應鏈
產業
區域
議題
觀點
漫新聞
聽新聞
每日椽真
商情
AI EXPO Taiwan
COMPUTEX
Research
半導體
IC製造
IC設計
化合物/功率半導體
運算
電腦運算
伺服器
邊緣運算
HPC關鍵零組件
通訊與雲端
寬頻與無線
次世代行動通訊
Cloud
未來車
CarTech
EV Focus
車用零組件
顯示科技
顯示科技與應用
AI & IOT
智慧製造
智慧家庭
物聯網
AI Focus
行動裝置
行動裝置與應用
智慧穿戴
新興市場與產業
Green Tech
亞洲供應鏈
新興科技
其他
全球產業數據
Research Insights
Special Reports
Tech Forum
服務
到府簡報
顧問專案
分析師團隊
椽經閣
首頁
Colley & Friends
作者群
活動家
首頁
DIGITIMES 主辦
智慧應用
雲端 & 資安
產品 & 研發
AI & 創新
其他
影音
英文網
Tech
Regions
Research
Opinions
Finance
Biz Focus
Event+
Multimedia
DIGITIMES
首頁
矽島.春秋
未來車供應鏈
蘋果供應鏈
產業九宮格
科技椽送門
展會
影音
科技網
首頁
未來車供應鏈
蘋果供應鏈
產業
區域
議題
觀點
漫新聞
聽新聞
每日椽真
商情
AI EXPO Taiwan
COMPUTEX
Research
半導體
IC製造
IC設計
化合物/功率半導體
運算
電腦運算
伺服器
邊緣運算
HPC關鍵零組件
通訊與雲端
寬頻與無線
次世代行動通訊
Cloud
未來車
CarTech
EV Focus
車用零組件
顯示科技
顯示科技與應用
AI & IOT
智慧製造
智慧家庭
物聯網
AI Focus
行動裝置
行動裝置與應用
智慧穿戴
新興市場與產業
Green Tech
亞洲供應鏈
新興科技
其他
全球產業數據
Research Insights
Special Reports
Tech Forum
服務
到府簡報
顧問專案
分析師團隊
椽經閣
首頁
Colley & Friends
作者群
活動家
首頁
DIGITIMES 主辦
智慧應用
雲端 & 資安
產品 & 研發
AI & 創新
其他
影音
英文網
Tech
Regions
Research
Opinions
Finance
Biz Focus
Event+
Multimedia
Research
搜尋
篩選
關鍵字
聯想
英業達
戴爾科技
惠普
亞馬遜
SiC
慧與科技
AI
氮化鎵
中國
全文搜尋
精準搜尋
或使用自然語言搜尋
篩選
搜尋
清除
報告類別
伺服器
亞洲供應鏈
車用零組件
EV Focus
寬頻與無線
邊緣運算
IC製造
Cloud
HPC關鍵零組件
物聯網
IC設計
化合物/功率半導體
智慧家庭
CarTech
電腦運算
AI Focus
Green Tech
新興科技
次世代行動通訊
顯示科技與應用
智慧穿戴
行動裝置與應用
智慧製造
上刊日期
過去三個月
過去六個月
過去一年
全部
-
分析師
林芬卉
羅惠隆
楊仁杰
翁書婷
簡琮訓
姚嘉洋
吳伯軒
張嘉紋
陳澤嘉
蔡卓卲
陳皓澤
張珩
王乙蓁
陳辰妃
申作昊
林俊吉
陳冠榮
黃耀漢
蕭聖倫
余佩儒
江明謙
黃雅芝
余君濤
周延
林欣姿
杜振宇
李鴻運
白心瀞
廖萱昀
羅婉甄
陳加鑫
邱欣蕙
方覺民
黃銘章
黃健治
搜尋
搜尋條件
搜尋關鍵字:應用程式介面
搜尋模式:精準搜尋
上刊時間:2004/03/03~2026-07/26
載入中
AI Focus
AI Focus
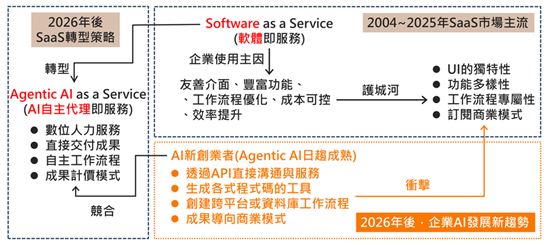
Agentic AI衝擊SaaS市場 8成SaaS業者面臨轉型為AaaS
DIGITIMES觀察,2004~2025年訂閱制SaaS長期主導企業營運用軟體市場,提供穩定且易用的訂閱方案;然而進入2026年,約8成SaaS業者受Agentic AI技術衝擊,面臨強大的轉型壓力。SaaS業者積極轉型為AI自主代理即服務(AaaS)模式,同時與AI新創業者建立競合關係,一方面自行開發Agentic AI服務,另一方面透過API整合與AI新創業者策略聯盟,共同為企業提供跨平台自主工作流程與成果計價服務的商業模式,SaaS業者轉型不僅因此建立新護城河,更穩固市場競爭力。...
黃耀漢
2026-04-20
AI Focus
AI Focus
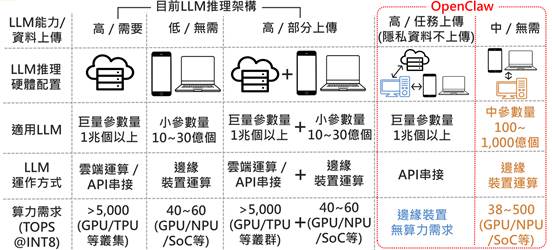
OpenClaw熱潮加速邊緣AI Agent個人化應用 帶動VPS與個人工作站需求
DIGITIMES觀察,OpenClaw熱潮加速AI Agent在個人應用領域的落地,用戶可透過多元通訊平台,讓AI Agent融入用戶日常生活。在LLM推論層面,OpenClaw可串接雲端L...
黃耀漢
2026-03-09
車用零組件
車用零組件
中國車用晶片自主化加速 地平線擴大中國高階自駕布局並攜手國際業者進軍海外
DIGITIMES觀察,中國政府近年加速推動車用晶片自主化政策,中系車廠自駕方案龍頭地平線在政策帶動下,成為主要受益者。地平線憑藉征程6晶片的高算力、軟硬體整合技術,以及高度彈性的合作模式,已將高階自駕產品搭載於多家中系車款中,並獲得國際主流車廠與Tier 1供應商認可,合作海外布局。...
廖萱昀
2025-11-12
寬頻與無線
寬頻與無線
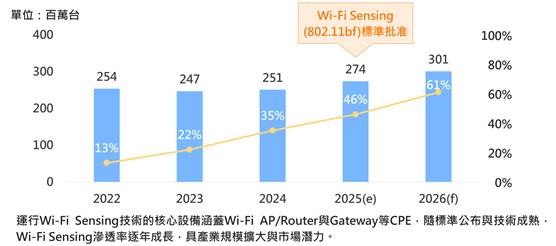
通訊技術結合環境感測功能 Wi‑Fi Sensing標準化加速應用落地
DIGITIMES觀察,Wi-Fi除做為無線通訊技術外,近年來也逐漸發展出通訊以外的新興應用,其中無線網路感測(Wi-Fi Sensing)即是發展趨勢之一,並成為2024~2025年全球...
王雨讓
2025-10-23
邊緣運算
邊緣運算
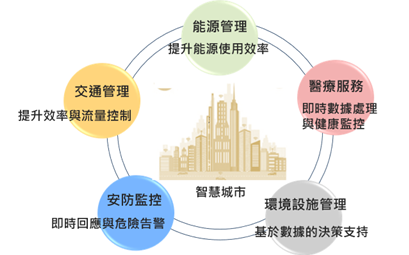
邊緣AI助力智慧城市相關場景落地開花 整合多樣感測數據提高感知與決策能力為趨勢
DIGITIMES觀察,邊緣AI在智慧城市推展上扮演重要一角,其將AI模型部署於攝影機等終端裝置上,以最低延遲,實現更快的本地分析與數據處理,有利進行智慧城市複雜的任...
DIGITIMES研究團隊
2025-08-22
物聯網
物聯網
從晶片商轉型IoT平台業者 高通、聯發科積極布局GenAIoT 競逐邊緣AI主導權
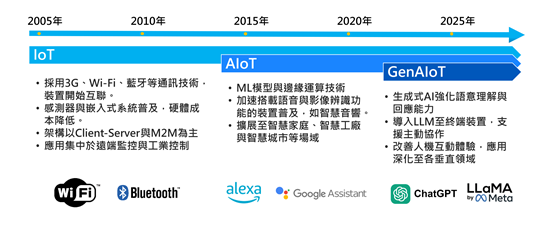
DIGITIMES觀察,生成式AI逐步向終端擴展,推動IoT邁入GenAIoT世代,終端裝置需具語意理解能力,強調高推論效能與低功耗特性,其中涉及邊緣AI算力、軟體工具鏈與通...
陳辰妃
2025-08-12
智慧家庭
智慧家庭
智慧家庭領頭業者Google、亞馬遜備齊資源 AI Agent或成下個勝負關鍵
DIGITIMES觀察,在智慧家庭領頭業者Google和亞馬遜(Amazon)相繼在智慧家庭語音助理導入生成式AI,且兩家業者也爭相推出新的軟體開發套件(Software Development ...
DIGITIMES研究團隊
2025-05-26
邊緣運算
邊緣運算
開源LLM推動地端推論需求 NVIDIA力圖主導邊緣AI算力商機
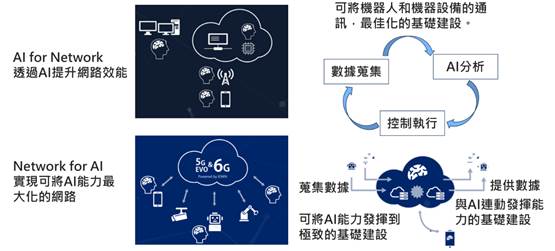
開源大型語言模型的發展日漸成熟,企業引入具成本效益,且能確保及逐漸增加資料主權的地端推論方案的可行性。在此背景下,NVIDIA迅速擴張產品線,將資料中心級的DGX...
DIGITIMES研究團隊
2025-05-23
寬頻與無線
寬頻與無線
NTT Docomo以AI-Centric Network為發展6G核心 聚焦AI與網路深度整合
DIGITIMES觀察,日本電信龍頭NTT Docomo以實現感官與感受即時共享、多感官的沉浸式體驗等應用,推動6G成為「與人深度融合的資通訊技術」為目標,積極投入太赫茲...
DIGITIMES研究團隊
2025-05-14
寬頻與無線
寬頻與無線
全球5G發展放緩 惟川普新關稅政策或有利中系業者擴張海外市場
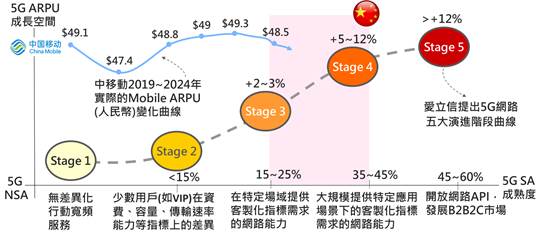
DIGITIMES觀察,全球5G發展已進入5G-Advanced新階段,然而商用普及速度明顯放緩。至2024年第4季統計,包括新增5G商轉網路數量、5G用戶數年成長率、新增5G基...
吳伯軒
2025-04-30
1
2
3
4
5
購物車
0
件商品
智慧應用
影音