


發展具特色的巨量資料技術應用
- DIGITIMES企劃
-

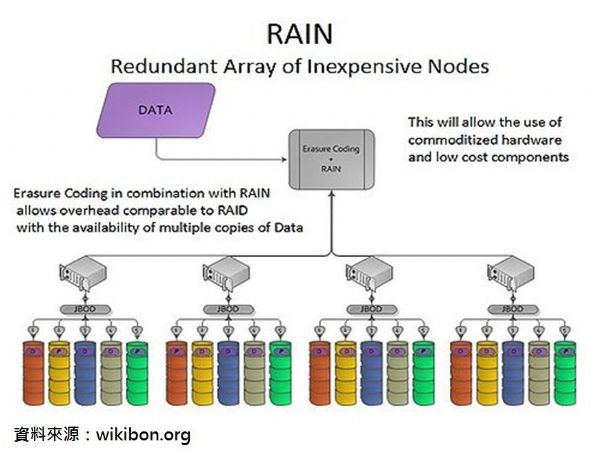
雲儲存的資料冗餘技術
傳統的儲存系統主要是透過RAID (Redundant Array of Independent Disks)的機制來實現資料的冗餘。當有硬碟故障時,若想要保證資料的完整性和可用性,須經歷RAID group的rebuild過程的痛苦。這是因為利用RAID機制的系統只能進行整顆硬碟的恢復;硬碟的容量越大,恢復時間就越長。在沒有其它負載的情況下,重建一個1TB硬碟大約需要10~12小時的時間,且此時間會隨系統負載增加而延長。 然而恢復的時間越長,發生資料丟失的機率就越高,所以並不適合用在分散式的雲儲存系統裡。
對於巨量資料應用的分散式儲存架構,則需採用RAIN (Reliable/Redundant Array of Independent/Inexpensive Nodes)的資料分片的方式,搭配上副本或可擦除代碼(Erasure code)的機制來實現資料的保護,並可提高平行的資料寫入和讀取的性能。

跨伺服器通訊:InfiniBand or Ethernet?
目前絶大多數高性能伺服器叢集之間都是使用InfiniBand互聯。主要是因為目前InfiniBand本身能提供比傳統乙太網更高的頻寬,再者是通常InfiniBand的protocol overhead比乙太網要小,對於節點間通訊大量資料傳輸效率比乙太網要更高。
關於頻寬方面,InfiniBand很早就推出了10Gb/s速率的產品,在10G乙太網仍未完全普及的今天,40Gb/s(DDR)和56Gb/s(QDR)InfiniBand已經成為主流,預計下一代技術將是100Gb/s(EDR)。
InfiniBand效率的優勢主要來自RDMA(遠端直接記憶體存取),使得在使用InfiniBand構築服務器、儲存器網路時,比10G乙太網以及Fibre Channel具有更高的性能、效率和靈活性。
然而乙太網技術的發展也持續進行著。例如相較其他廠商積極的Emulex也大力推動基於融合型乙太網的RDMA(RDMA over Converged Ethernet,RoCE)解決方案,這項技術今年將會廣泛應用在他們的10G乙太網市場,並且將進一步支持RoCE(融合乙太網上的RDMA)的下一代40/100GbE解決方案,企圖利用成本和性能的優勢,使其可以從InfiniBand提供商手中贏得一些HPC市場占有率。
另外,Intel與Facebook合作開發了新一代資料中心機架技術:Intel 100Gbps矽光技術 (Intel Silicon Photonics Tech.),其目的在減少使用纜線數量、提高頻寬和延長連結距離,並達到極高的電源使用效益,並將機架內現有的資源,包括運算、儲存、網路、以及電源配送等,拆分成多個單獨的模組資源種類集中配置成組,並分散至機架的各處,藉此改善可升級性、彈性、以及可靠度,並減少開銷。據該公司宣稱將大幅改變未來十年分散式機架伺服器設計,值得密切注意。
針對應用,挑選技術架構
巨量資料相關的技術一直不斷地在演化,而且呈爆炸性的發展,並具備著無可匹敵的開源優勢。然而在技術與架構的挑選上,仍需要非常的謹慎小心。
以往,很多人以為巨量資料分析就是Hadoop,使得非網際網路行業的許多應用都以Hadoop技術為核心來設計系統。事實上,在過去它只是一種批次(Batch)處理的技術,並不適合線上即時回應和一般企業SaaS的應用(如線上CRM)需求,而必須要有進一步的優化以拓展其應用性(如前述Intel所做的努力),或搭配像Cloudera公司的兩個開源新項目:Impala和Trevni,使得Hadoop以實現即時查詢。
Google也曾經一度認為未來幾乎所有的軟體都可以搬到網上,以服務取代軟體;認為雲端運算將使「終端」性能極度被削弱,因此強調純雲端的發展。但是現階段,Google不只承認「端」存在的必要性,甚至進而推出了平板電腦、手機、Google眼鏡和Google手錶等智慧型終端。Gartner 2014年十大策略性技術趨勢的第五項:「雲端/終端架構」(Cloud/Client Architecture)再一次提醒了我們較為適切的「雲+端模式」。
Google Big Table一度掀起NoSQL/最終一致性/key-value資料庫的革命,然而NoSQL也因為不支持SQL查詢和ACID而讓自身一直處於大量批評與質疑的聲浪之中,最終Google不得不承認缺失,而從NoSQL(Big Table)投向NewSQL ( Spanner) 的懷抱,如此,既保留了關係型模式的優勢(SQL查詢與ACID),又具有NoSQL的擴展性和靈活性。
像Google這樣等級的大公司,都有可能誤判情勢,做出錯誤的決策,更何況是規模與資源相對少很多的中小企業,稍一失策,輕則貽誤商機,重則元氣大傷江河日下,一去不復返。
巨量資料與SDN
巨量資料系統是一個隨業務量擴增而擴張的架構,是一個典型的集群系統,會產生大量的節點間資料。與傳統的資料庫系統相比,具有完全不同的流量模型。
而Hadoop,這個主要的巨量資料分析框架,在不同的階段所產生的網路流量是不一樣的,包含MapReduce演算的整個資料處理過程對網路提出了在頻寬、交換機buffer queue、網路拓樸和時延上比較獨特的需求,加上近年來出現了一些要求更高的即時Hadoop系統,故已開始有針對SDN(Software Defined Network)在巨量資料上的應用。此外,亦有將巨量資料與SDN結合,以實現自防禦網路的研究。
計算+儲存+軟體定義儲存 = SAN-Less
Gartner 2014年十大策略性技術趨勢的第八項「網路規模IT」(Web-Scale IT)說明的是一種全球級的運算形態,藉由多個層面的重新思考定位,在企業IT環境當中提供大型雲端服務供應商的能力。部分大型雲端服務供應商,如Amazon、Google、Facebook等等,正重新打造IT服務的供應方式。他們的能力不單只在規模大小,還有速度和靈活性。企業若希望與這些模範雲端服務供應商並駕齊驅,就必須仿效其架構、流程和實務方法。
Nutanix似乎已預先看見了這個趨勢,將源於大型雲端服務供應商的資料中心的分散式精簡架構設計概念,從公有雲帶入了企業私有雲。該公司係由一個曾經開發Google file system等可伸縮系統和甲骨文資料庫 / Exadata等企業級系統的團隊於2009年創立,獲得多家創投公司的投資。
據該公司宣稱是第一家提供這種融合運算與儲存於一體的精簡架構的公司,這種架構不需要複雜、昂貴的外部網路儲存設備(SAN或NAS),通過Nutanix Distributed File System(NDFS)技術,讓多台服務器中硬碟,組成統一的集群儲存池,共享儲存空間,就能實現企業級的虛擬化。相較於傳統架構,移除昂貴的外部儲存設備後,可降低40%至60%的資本支出(CapEx)。
在虛擬化的優秀表現也讓其在2013年VMWorld大會中,再度榮獲Best of VMWorld殊榮,同時也是全球唯一連續三年獲得該項榮耀認可的廠商。
「巨量」 資料的省思
雖然價值顯而易見,但仍有人針對巨量資料提出實用上的質疑,例如:並非每一項分析都需要用到「巨量」的資料,盲目的追求「巨量」資料,並不能帶來資料分析的絕對性與正確性。此外,不論是企業或是科學界,資料的「品質」往往勝過資料的「數量」!一個經典的例子:孟德爾(Gregor Mendel)在解析遺傳基因密碼的過程中,靠的僅僅是一本筆記本的資料,而並不是透過大量的資料分析。
我們認為:有關巨量資料價值的爭議是沒有必要的!畢竟,有些問題適合透過巨量資料分析求取答案,有些卻不需要、也不適合!我們應該把目光的焦點,放在巨量資料分析方法背後所代表的真正意涵,以及針對問題的特性找到最合適的解答方法和參數模型。
當我們透過巨量資料分析獲取價值的同時,我們同時也抓取大量的資料、佔用了大量的儲存空間,並可能為此設置新的資料中心;這不僅增加了企業組織的成本,也因設備的添置與維運耗用更多的能源。為此,巨量資料時代的來臨也將帶動節能減碳的需求,例如能源管理新模式的探索,以及智慧電網的應用。
(專欄作者:台灣高科技製造公司技術長黃瑞安博士、資深工程師賴銘祥。本專欄已刊載完畢。)






{kind=link}