


Hadoop與MapReduce 開發巨量資料應用
- 闞大成
-


工欲善其事,必先利其器,縱使巨量資料寶庫蘊藏豐沛的珍寶,然而意欲挖掘出這些寶寶,企業所需準備的工具,仍是以往慣常採用的關聯式資料庫、SQL語法、ETL(Extract、Transform、Load)嗎?當然不是!除了幾乎成為巨量資料代名詞的Hadoop外,以及相同框架裡頭的MapReduce、HDFS等技術,企業皆需勤加研習。
當巨量資料鋪天蓋地攻佔IT專業媒體重要版面,許多過去仍對此一知半解的企業,也不得不修正隔岸觀火的心態,開始花時間加以研究,結果發現,世界上很多赫赫有名的企業,都早已熱情簇擁巨量資料,並獲得豐碩的應用成果,那麼事不宜遲,得緊搭上這個熱潮才是。
只不過,對於RDBMS、SQL語法、Schema等一干東西早已駕輕就輕的IT人員,如今銜老闆之命研讀巨量資料,卻發現裡頭盡是陌生的名詞,例如老是以1頭黃色大象來示意的Hadoop,所有關乎Big Data的辭彙中,出現頻率最高者,接著一探究竟,才發現它被喻為是最適合用來處理、儲存及查詢巨量資料的平台,既然Hadoop如此備受好評,就算過去對它不嫻熟、未來也不打算考取它的證照,但至少不能繼續對它懵懂無知。
主因在於,意欲開啟巨量資料希望之門,幾乎可以肯定,絕對少不掉Hadoop這把鑰匙!
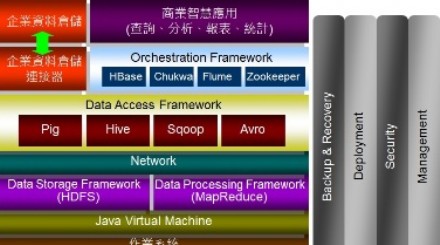
Hadoop框架之中,擁有兩大支柱
對於已經老到不想再啃書本,或者實在離不開Schema資料庫結構的人士,一旦往Hadoop軟體框架裡頭鑽研,頓時頭皮發麻,真的很想棄械投降,但心想不論是巨量資料、甚或雲端運算等熱門話題,全都與這些玩意相關,所以不管再怎麼痛苦,也只有硬著頭皮繼續K下去。
Hadoop之中所有相關聯的「法器」,到底有哪些?其中有兩個最為核心的項目,一是MapReduce這個執行分散式處理的程式模型,另一則是HDFS這個虛擬的分散式檔案系統,透過專司運算、儲存的兩根大支柱,牢牢地撐起Hadoop架構。
首先談到MapReduce。回顧大家較為熟悉的商業智慧(BI)運作模式,其必須從多個系統當中,將分析模型所要的資料予以彙集,因此勢必得歷經1道讓許多IT人視為畏途的程序,那便是ETL(Extract、Transform、Load);如今進入巨量資料世界,MapReduce就彷彿扮演ETL角色,負責為原始資料進行加工處理。
事實上,MapReduce可分為「Map」、「Reduce」兩大段落,前者是1個從(key, list(value)) 對應到list(key', value')的函數,顧名思義就是拿著這把Key,與每一筆資料進行配對,然後整理出中繼資料;至於Reduce,則是1個從list(key', value')對應到list(value'')的函數,負責將許多value'、也就是各個中繼資料,收斂成為1個value''。
而在Hadoop系統架構中,通常會動用大量名叫「Worker」的工作單元,接受「Master」的指揮調度(由JobTracker先將任務指派給TaskTracker,然後才交辦下去),分頭執行Map與Reduce任務;這些Worker各自做完這些工作後,會將成果回報給TaskTracker。
其次說到HDFS分散式檔案系統,與前述Master節點亦脫不了干係,Master麾下有JobTracker與TaskTracker負責傳遞運算任務,也有NameNode及DataNode等另外兩名大將,職掌資料的分配事宜。
NameNode的功能與傳統檔案系統有類似之處,都會把1份檔案切割成許多Block,然而傳統檔案系統會將這些Block儲存在同一台實體主機的硬碟之中,NameNode則不然,會把Block分散到不同DataNode上;對於懂得Linux技術的人士,此時難免會有似曾相識之感,因為NameNode活脫脫就像Linux檔案系統裡頭的Inode,如果有人要問,某份檔案的所有Block,究竟都被安置於何處?唯獨Inode或NameNode這類型的要角才能給出答案。
如此一來,當使用者需要讀取某特定檔案,就可在NameNode的幫助之下,讓原本各自存放1個Block的5台主機,把這些Block釋放出來,而使用者一連讀了5個Block後,再將它們組合成為完整檔案,此一模式的好處是效率很高,否則如果是從同1台伺服器依照順序讀取Block 1~5,其間光是頻頻的讀取鎖定(Read Lock),恐怕就足以讓人心浮氣燥。
不過話說回來,如果沒有太多經驗,一開始想要寫好MapReduce程式,恐怕也沒這麼簡單,有時光是一些看似不起眼的小錯誤,就可能讓程式開發人員處於鬼打牆情境,久久不能重回正軌;所幸隨著巨量資料議題發燒,有廠商開始設計出頗易上手的Hadoop套件,以微軟為例,便將其累積自Bing搜尋技術、SQL Server資料採礦技術的智識,打包成為一個個Template,並透過Azure市集以App型式提供出去,有了它的幫忙,程式開發人員即可免於走許多冤枉路,從加速完成MapReduce程式的開發,且有助於提供程式內容的正確性。
伴隨相關輔助工具愈趨成熟,其實不管IT人員是老或少,都能更快進入情況,實在無需把Hadoop或MapReduce想像得如此恐怖。
除了雙箭頭,尚有多名小悍將
除了MapReduce、HDFS「雙箭頭」外,環顧整個Hadoop軟體框架,裡頭其實還有不少利器,值得有志投入巨量資料的企業善加利用。
前面提及MapReduce程式撰寫的難度,其實光是擁有「Mahout」這項工具的輔助,就能省卻不少麻煩;主因在於,Mahout就是1套MapReduce函式庫,其間有一些現成的範本,方便程式開發者予以呼叫使用,大幅減輕了撰寫程式方面的負擔。
此外有1個稱作「Pig」的東西,也足以紓解MapReduce程式撰寫的壓力。Pig的全名為Pig Latin,它是專門設計用來執行巨量資料分析的語言,由於大量選用諸如GROUP、FILTER或JOIN等親和力甚高的指令,讓人非常容易上手,而Pig亦能將此處產生的腳本程式,自動轉換為MapReduce Java程式,等於是提供了另1條捷徑。
其餘諸如「HBase」這個植基於Column的Hadoop資料庫系統,以及有些類似SQL語言、但卻又不是SQL語言的「Hive」或「HiveQL」,其實與前述的Mahout或Pig Latin一樣,皆有異曲同工之妙,可以發揮相當程度的妙效,使得門外漢要想一窺巨量資料之堂奧,變得相對簡單許多。
走搜尋引擎路線,輕鬆踏進Big Data世界
對於經常參與巨量資料研討會,並不時研讀相關文獻的人們,一定都曾聽聞過Splunk這個名詞,這家以「時間序列搜尋引擎起家」、並以「IT Google」自我定位的公司,運用了相當特別的解決方案,標榜可以讓完全不懂Hadoop、也從未部署任何BI工具的企業,亦能迅速走進Big Data世界,乍聽之下,利基點其實不少。
Splunk之所以打出獨樹一幟的訴求,主要緣自於單一平台的多功能性,無論是資料蒐集、運算、儲存、查詢、索引、分析、監控或展現,各式各樣的需求,通通都被包覆在內;假使企業一方面得大費周章建造Hadoop環境,二方面又得基於特定分析主題,逐次以撰寫程式方式,手動將Hadoop資料送進資料倉儲,相形之下,包羅萬象的Splunk,確實具備不小親和力。
不過強項在於分析「機器資料」的Splunk,雖然可有效掌握了巨量資料當中增長速度最快的一環,但機器資料畢竟是一環、而非全貌(例如無法分析影像圖檔資料),與其兀自一手遮天,倒不如與Hadoop整合運作,方能發揮最大綜效。
而Splunk就真的這麼做,已經推出與Hadoop整合的套件;如此一來,用戶可將Splunk資料轉入Hadoop、以利推動學術研究,亦可將Hadoop轉至Splunk、執行視覺化分析、報表產出等任務,透過兩者合璧,連帶也填補了Hadoop即時性不足的罩門。
其實說起亞太區第一個Hadoop應用案例,是發生在2009年,當時中國移動研究院運用Splunk萬用搜尋引擎技術,在Hadoop分散式處理架構中,推動電信通話紀錄(CDR)資料的分析任務,顯見兩者之間聯袂運作的必要性,早已有跡可循。






{kind=link}