


企業挖掘巨量資料 可望獲得致勝線索
- 闞大成
-


綜觀2012年各項IT話題,若說「雲端運算」是所向披靡的大熱門,除此之外,少數堪能望其項背者,無疑正是「巨量資料(Big Data)」;探究它之所以如此吸睛,乃在於愈多企業認為,要想探索致勝方程式,掌握營運成長動能,從巨量資料挖掘準沒錯!
事實上,可被翻譯為「巨量資料」、「海量資料」或「大數據」的Big Data,並不是才剛初來乍到,正如同許多機器設備,絕非現在開始產出Log一般,但過去別說拿它來當作決策制定的依據,多數企業的執行長甚或資訊長,恐怕都鮮少用正眼瞧過它。
但過去幾乎無異於「垃圾」的巨量資料,竟然在最近3年內迅速由紅翻黑,不僅成為研究機構熱衷的題目,IT專業媒體報導的重點,被設定為研討會主題的機率,也不斷攀升;若干不明就理的人不禁納悶,巨量資料到底在紅什麼?
有人認為,巨量資料的崛起,與Web、Video、行動應用、社群媒體等趨勢浪潮,有著很大的關係,正因為這些非結構爆量增長,也才成就了「Big」,亦即「巨量資料」的4V特性當中的Volume;但是量大、不代表價值大,如果價值不大,產官學各界菁英絕不會花那麼多力氣去討論它,資深IT人犯不著重拾書本猛K「Hadoop」、「MapReduce」或「Hive」,企業主更不可能同意放行這麼一大筆投資案,為了推動巨量資料應用而購置大量軟硬體系統。
此時不妨以結果論英雄。由於產官學菁英、資深IT人或企業主都不是無聊人士,絕不可能賠上這麼多的精神、時間或金錢,圍繞著「體量碩大」但「價值平平」的Big Data打轉,因為過去曾有不少人試圖炒熱某些議題,也期望爭取這些人士的關愛眼神,但他們多半不為所動,事後也證明這些議題並無太大價值,這就說明了,巨量資料肯定富含價值,而且價值還不是普通的大,才得以讓各路英雄好漢出手。
那麼,巨量資料從早期棄若敝屣、束之高閣,演變到今天一群人捧著鈔票去追逐它,事出必然有因,難免讓人好奇,這個「因」,到底所為何來?
成功企業燭洞機先 產生示範效應
早在巨量資料捲起千堆雪之前,業界老早談了10年以上的商慧智慧(BI),期望透過線上分析處理(OLAP)、資料探勘(Data Mining)或資料倉儲(Data Warehouse)等一干技術,從營運數據中抽絲剝繭,進而鑑往知來,延續並強化所有的成功元素,革除並導正所有的失敗元素,藉此不斷優化經營體質。
事實上,BI應用確實有其價值,但唯一讓人覺得有所缺憾之處,在於它僅能針對來自於ERP、CRM、SCM等應用系統的結構化資料做分析,而這些數據,通通都是木已成舟的事實,因此在過去很長一段時間,BI充其量是幫助用戶成為「事後諸葛」,但至少比起瞎子摸象,肯定強過不知多少倍。
然而如今,就連傳誦已久的Wal-Mart「啤酒與尿布」故事,都不再引起人們太多興奮,這似乎說明了,一再分析01010101…等結構化資料的BI,已不足以讓企業「如有神助」,亟需找尋其他可供商業分析的新養分,才得以彰顯應用價值;於是乎,有腦筋動得快的人,便將矛頭指向了體量更大的非結構化資料,期望能藉此帶動另一波資料分析高潮。
這步棋,還真是走對了!主因在於,隨著行動應用、社群媒體等新興應用的竄紅,普羅大眾「黏」在這些應用的時間,比起從前透過電腦進行的文書應用,可說大幅延長,更值得一提的,人們也開始拋開從前的矜持,不再隱藏內心深處的獨白,轉而願意對社群好友講真話、分享訊息;換言之,現今的非結構化資料之中,著實蘊藏了許多的真實意向的表達,這些意向有可能從少數幾個人的發想,迅速蔓延成為眾多鄉民的集體共識,繼而對某些商品的採購、對某些品牌的好惡,造成深遠而巨大的影響。
等到藉由ERP或CRM等實際數據出爐後,再來做事後分析,早就為時已晚,無法幫助企業實現趨吉避凶之目的。因此有些極具全球指標性的網購或零售業者,開始試圖拆解非結構化資料,期望從中挖掘更多的蛛絲馬跡,得以在人人皆曰「往東」時,先一步看出形勢悄然轉為「往西」的變化,據此進行相對應的資源調度與分布,及早從即將彎頭向下的市場中抽身,並針對即時翻揚的市場優先卡位。
諸如此類洞燭機先的成功案例,足以形塑莫大示範效應,使得大家都紛紛意識到巨量資料的魅力,並且開始起而效尤。
參透4V特性,做好必要準備
綜此,人們也就不難理解,為何那些倡導巨量資料應用的人士,開宗明義一定先介紹3V,也就是Volume、Variety與Velocity。此乃由於,它的量真的夠大(Volume),所需消化的速度也得夠快(Velocity),否則依照ReadWriteWeb說法,如今只消短短兩天,即可創造人類開天闢地以來直至2003年所累積的資料量,但即便資料增長速度令人咋舌,絕不意謂企業可以好整以暇慢慢處理資料,相反的,最好還能養成即時處理的能力,否則對於商業決策的制定品質與速度,必然產生不利影響。
至於另1個V-Variety,其實更是殆無疑義,因為舉凡電子郵件、TXT文字檔、Excel、語音、照片、影像等形形色色的非結構性資料,在在都屬於巨量資料範疇,其型態之多元化,比起從前結構化資料定於一尊的態勢,明顯截然不同。
不過,或許3V還不足以闡述巨量資料的特色,於是後來又有人加入了第4個V,也就是價值(Value),如同前所描述,巨量資料若非蘊含豐沛的開採價值,一干人等決計不會對它趨之若鶩。但說到價值,固然可以價值的高低加以形容,但在另一方面,其實亦可透過「價值密度」予以表彰,可以肯定的是,巨量資料的價值密度不僅不高,而且算是極度偏低。
所以我們可以這麼形容。如果巨量資料就好比1座寶庫,那麼這座寶庫裡頭,確實擁有「價值連城」的不世珍寶,值得企業善加挖掘,但可千萬不要以為,寶庫內遍地都是蹴手可得的黃金,1粒不世珍寶,或許與9,999粒毫無價值的沙礫,一起被包覆在同樣1個泥塊裡頭,其「價值密度」可能低到萬分之1之譜。
既然價值密度偏低,絕不可能隨手一撈就有大收穫,好好地因應巨量資料處理,備妥必要的工具、程序、方法及流程,設法增加開採速度,方能提早發現到絕世瑰寶,讓自己真的是「滿載而歸」,而非入寶山卻一無所獲,灰頭土臉淪為「鎩羽而歸」。
看準了企業都需要巨量資料的挖寶工具,所以檯面上的一線大廠,早已著手展開布局。IBM從2005年接續購併FileNet、Cognos、ILOG、SPSS、OpenPages、Algorithmics等超過30家公司,已然匯聚成為強大商業分析能量;此外,HP在2011年間收編Autonomy與Vertica兩家公司,EMC則從2009年起一連收購Archer Technologies、FastScale Technology與Varonis Systems等企業,種種舉措無一不是衝著巨量資料而來。
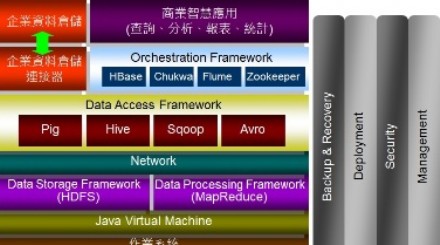
至於眾廠在Hadoop方面的投入,那更是高潮迭起,其中包括甲骨文、微軟等主流資料庫廠商對於Hadoop的鼎力支援,連EMC也宣布將此整合到Greenplum之中,再加上IBM 所推出的InfoSphere BigInsights,亦是建構在Hadoop上的資料分析軟體。
因此可以篤定,Hadoop將在巨量資料世界扮演中流砥柱,對於企業而言,它將會是前進Big Data寶庫的過程中,不得不修煉的武功心法,其重要性明顯凌駕NoSQL或R分析。






{kind=link}